
Try googling for the phrase “anonymization is impossible”. You’ll get plenty of hits. The idea that anonymization is impossible, or at least very very hard, is widespread. Another widely held belief is that Differential Privacy, with its mathematical guarantee of privacy, is the only way to reliably anonymize data.
In stark contrast to these beliefs is the simple fact that it is very hard to find reports of malicious re-identification of de-identified (anonymized or pseudonymized) data. I have looked hard for any such reports, and asked many colleagues if they know of any reports. The only thing I’ve been able to come up with are attacks on early releases of the New York City taxi dataset, which were poorly pseudonymized. The attack identified and publicized some celebrities that allegedly didn’t tip well (without considering the possibility that maybe some taxi drivers don’t record their tips well).
Virtually all reports of re-identification come from white-hat attacks carried out by academics or journalists, which I don’t regard as malicious. Of course just because there are no reports of malicious attacks on de-identified data doesn’t mean that they don’t happen. Nevertheless I have to believe that if these attacks were commonplace we’d hear about them from time to time.
My intuition is that successful malicious attacks on de-identified data are in fact extremely rare — not only because of the lack of evidence of these attacks, but also because there are many ways to thwart a potential attacker.
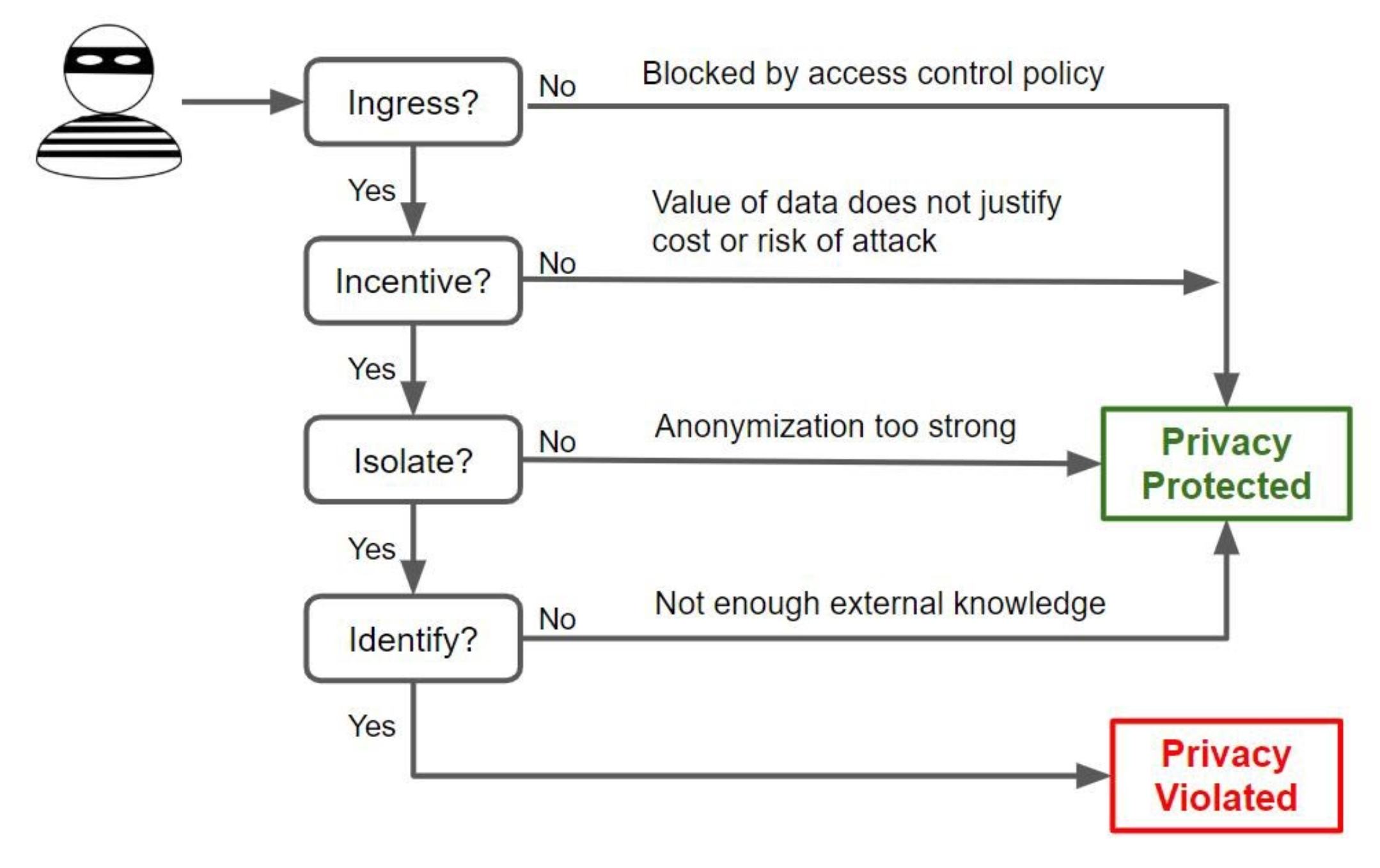
In this first of a series of articles, I introduce four conditions that are required for re-identification: Ingress, Incentive, Isolation, and Identification. I call these the private eyes. Later in the article I give several examples showing the importance of utilizing as many of the private eyes as possible.
Ingress
The first condition for re-identification is simply that the attacker has access to the de-identified data.
Unless absolutely required, a data controller should never openly release de-identified data to the public.
Incentive
A second condition for re-identification is that an analyst (the person with access to the de-identified data) has an incentive to re-identify. Incentive exists when the benefit of re-identifying the data outweighs the cost and risk.

To increase an analyst’s risk, an effective and commonly used approach is to contractually prohibit the analyst from attempting re-identification. This approach is used for instance by the HCUP healthcare databases, among many others. Better still if the analysts’ actions can be monitored, for instance by requiring that the analyst work with the data on devices controlled and monitored by the data controller. When data is only pseudonymized or weakly anonymized, as for instance is the case with de-identification based on HIPAA safe harbor, then contractual oversight is a must.

The cost of re-identification increases as the strength of de-identification increases. As more de-identification mechanisms are brought to bear, like aggregation, adding noise, data swapping, and top- and bottom-coding, the difficulty of re-identification increases. This can remove incentive altogether, or simply make it less likely for a still-incentivized attacker to fail. Indeed the very definition of anonymous is often that data has been de-identified to the point where the cost of re-identification far exceeds the benefit.
Isolate
Supposing that an analyst has access to de-identified data and the incentive to re-identify, the analyst must necessarily be able to somehow recognize individuals in the data. Strong anonymization mechanisms make this hard to do. K-anonymity, for instance, ensures that any given individual in the dataset is identical to at least K-1 other individuals. Without specific additional knowledge, it is not possible to recognize, or isolate, the data of a single individual. Aircloak’s Diffix brings both classic and new mechanisms in an automated dynamic query system. If an individual cannot even be isolated, then it is not possible to re-identify the individual.
Identify
Just because an individual has been isolated does not mean that re-identification has occurred. For instance, suppose that an analyst has access to a dataset containing geo-location information, and determines that there is a only single individual that has been in certain places at certain times. Although that individual has been isolated, if the analyst does not know who that user is, that is, cannot associate personal information like name and address to the individual, then the individual has not been re-identified.
Intrusion
There is a fifth private eye that we leave for last because it is more philosophical than technical. Namely, Intrusion. Assuming that an individual has been identified and information about the individual has been learned, does that individual actually feel that his or her privacy has been violated? In other words, does the individual feel intruded upon?
An interesting case is that of the AOL search data release, which contained pseudonymized search data. A journalist identified a woman in the data, contacted the woman, and got her consent for using her name in an article. We can’t know whether or not she in fact felt that her privacy was violated, but since she gave consent then perhaps in some legal sense we may say that it was not. (I find it interesting to consider that, had the woman felt her privacy was violated, then the mere fact that the journalist identified her, even without naming her in the article, might have constituted a privacy violation.) The fact that the only person identified from the data release was ok with it didn’t stop AOL from being sued.
GDPR defines certain categories of personal data as sensitive, and requires additional protections. These include:
- personal data revealing racial or ethnic origin, political opinions, religious or philosophical beliefs;
- trade-union membership;
- genetic data, biometric data processed solely to identify a human being;
- health-related data;
- data concerning a person’s sex life or sexual orientation.
As I show in an example below, the fact that some personal data is not defined by GDPR as sensitive, and indeed would not be regarded as sensitive by most people, should not lead to complacency. Data controllers should take the attitude that all personal data is sensitive.
Isolate versus Identify
The difference between isolating and identifying is the basis for a lot of confusion. The common everyday notion of anonymity is that of being able to identify a specific individual. For instance, when a policeman asks you for your identification, he has already “isolated” you in so far as you are a specific person there in front of him. One doesn’t normally think of isolating as a necessary step in breaking anonymity.
The confusion surrounding these concepts was widespread enough that the EU Article 29 Data Protection Working Party Opinion 05/2014 on Anonymisation Techniques defines two forms of de-identification: anonymous and pseudonymous. For data to be regarded as anonymous, and therefore no longer personal data, it must be for all practical purposes not possible to even single out (isolate) an individual in the data.
Data where personal information like names and addresses have been removed, but where individuals can be easily isolated is pseudonymous and regarded as personal data by GDPR. Researchers have shown time and again that pseudonymous data can be re-identified with external knowledge. While there may be cases the necessary external knowledge simply does not exist, but this is hard to know for sure, and the GDPR does not want to go down that slippery slope.
Examples
Netflix
In 2007 Netflix launched the Netflix Prize, an open competition to improve on Netflix’ recommendation system. Netflix publicly released a pseudonymized dataset containing the movie ratings for nearly 500K individuals. The dataset contained no personally identifying information: individuals were identified with a numeric value.
In the nomenclature of the five private eyes, Netflix only implemented Identity protection. Protecting against Isolation was almost certainly not an option because of the resulting degradation of data quality. Netflix believed that pseudonymization provided adequate protection. Perhaps they also believed that in any event the data was not sensitive and so would individuals would not feel Intruded in any event.
In 2007, researchers from UT Austin discovered that individuals in the dataset could be re-identified by correlating the Netflix data with IMDb reviews. The researchers argued that sensitive data could potentially be released by inferring for instance sexual preference or political affiliation based on the movies the individual reviewed. The re-identification attack led to a lawsuit in 2009 that was settled out of court, and ultimately Netflix canceled the Prize in 2010.
HCUP
Like Netflix, the Healthcare Cost and Utilization Project (HCUP) releases pseudonymized data for research purposes. The HCUP data is medical data, and so is certainly sensitive. Also like Netflix, strong anonymization would degrade data quality too much.
Unlike Netflix, HCUP protects its data at all levels. HCUP does not publicly release data. At Ingress, HCUP vets recipients and requires, among other things, that they pass a test showing that they understand their responsibilities. At Incentive, HCUP enters into a contract with the data recipient and places legal liability on recipients for not protecting the data. The contract includes a provision that prevents the recipient from even attempting to re-identify individuals in the data. While individuals are isolated in the data given to recipients, recipients are required to aggregate the data in groups of at least 10 individuals when publishing research results based on the data.
There are no known incidents of re-identification of HCUP data (according to HCUP in a private email exchange). By protecting at all levels, HCUP enables valuable health research. I am convinced that Netflix could have avoided its problems by implementing HCUP’s procedures.
Mobility Data
A number of companies, for instance Teralytics, sell mobility data: data from cellular phone services or GPS. Although not one of the GDPR-defined sensitive data categories, mobility data is nevertheless highly sensitive, and companies entrusted with that data protect it fiercely. Although these companies protect at all levels, they focus on ensuring that individuals cannot be isolated. For instance, Teralytics heavily aggregates both time and location, and filters out any data points that refer to too few individuals.
Defense in Depth
Data controllers should bring defenses to bear on all of the four technical private eyes: Ingress, Incentive, Isolate, and Identify. In spite of advances in anonymization technology in recent years, in many cases it may not be possible to anonymize data and still satisfy the analytic use case. When this is the case it is absolutely essential that data be pseudonymized, and that access is given to the fewest possible analysts under the strongest possible contractual arrangements.
Even when anonymization is possible, however, defenses at all other private eyes should be used. After all, you never know when something might go wrong. With multiple defenses, an error in one defense is mitigated by the others.
Stay tuned!
Keep an eye out for the next installment, “The Five Private Eyes Part 2: Marketers, Journalists, Prosecutors, Academics, and Spies”
Categorised in: Anonymization, Anonymization, General, Privacy